
{kind=link}
One of the reasons I am so passionate about Linux is because no matter how long you have been working with it, there is always something new to learn. The column command is a case in point.
The column command allows you to columnate (I don’t think that is a word, but the man page does) a list. It’s a neat little utility and I can see this coming in handy, especially when working with csv (comma separated value) files, or any file using a delimiter, on the command line. Also the JSON output format might be useful for some developers.
The column command uses the $COLUMNS environmental variable to figure out the size of your terminal. With this information it determines how many and what size columns to display. If you are using a small terminal window the output may not be put into columns if the utility determines it doesn’t have enough space.
I apologize in advance if the images make it hard to read the code. Writing this tutorial presented some challenges. Although the column command is spiffy on the command line, those columns do not translate well when posted into a online editor.
Displaying Output in Columns
The core purpose of the column command is to display output in columns. You can do this by simply passing a filename as an argument to the column command. In the example below we are using the file /usr/share/dict/words. It is just a giant list of dictionary words, one word per line.
$ column /usr/share/dict/words
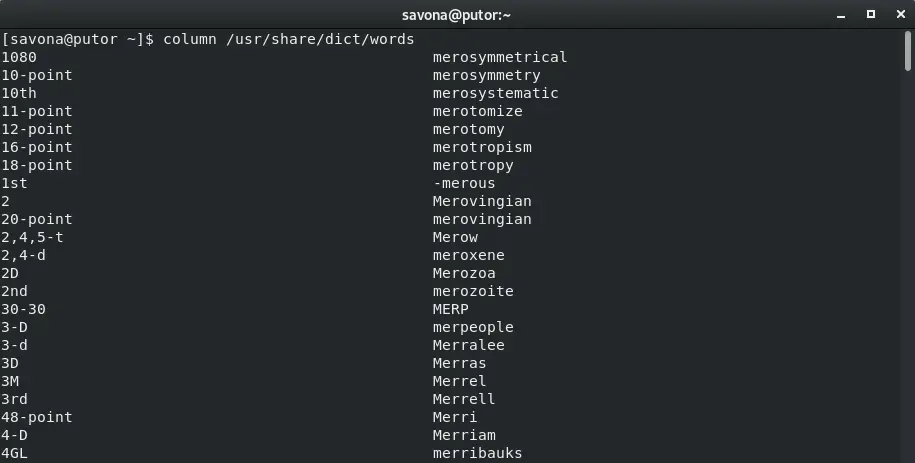
As you can in the screenshot above, the column command made two columns out of the list of words in the file.
Creating a Table
The column command can determine the number of columns the input has and create a table. Simply pass the -t option to create a table.
$ column -t rock.csv
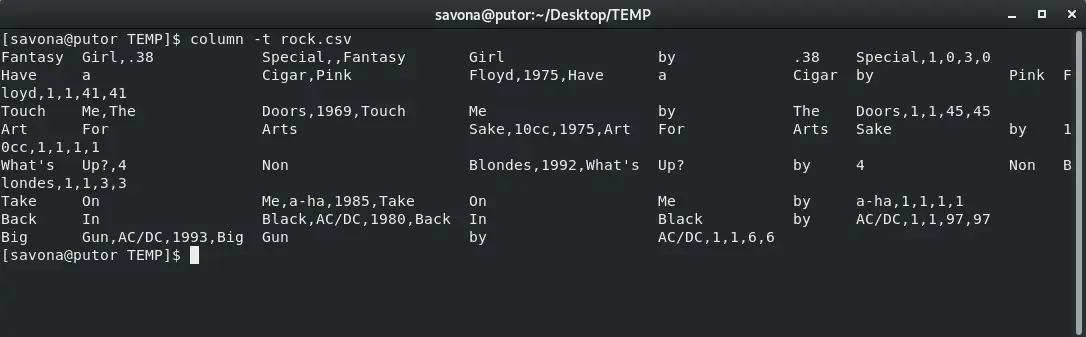
In the screenshot above you can see that we created a table using the input file rock.csv which contains playlist information for rock songs. The output is messy and unorganized because the default separator is a space. If the name of a song (or any value) has a space in it, it will occupy more than a single column (split on spaces). We can fix that by setting a custom separator.
Using a Custom Separator (Delimiter)
This is where the column command gets really useful. You can specify a custom delimiter to tell the utility when it should split into a new column. This file is a csv file (comma separated value) so we will use the -s option followed by a comma to declare it as a separator.
$ column -s, -t rock.csv
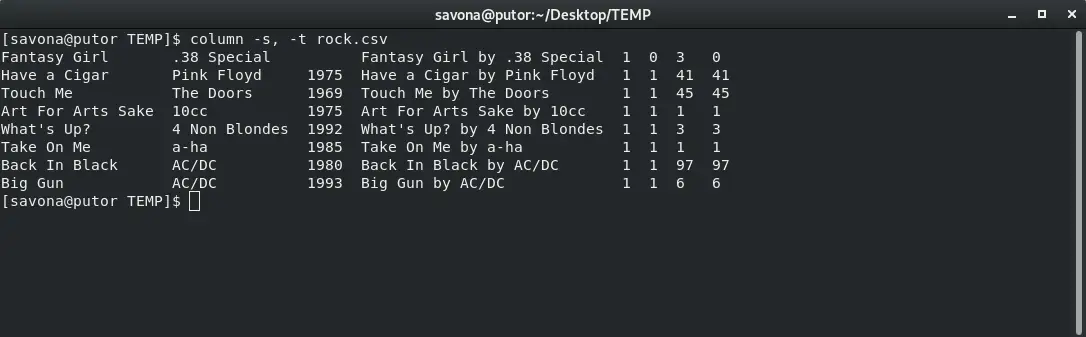
That’s much cleaner.
Specify Column Names
You can specify the column names for a table header. The names are used to address the column for additional options. Here we will add custom headers which will make the output even more human friendly.
You can specify the column names by using the –table-columns ( or -N ) option followed by a list of names separated by a comma.
$ column -s, -t --table-columns TITLE,BAND,YEAR,COMBINED,FIRST,YEAR,PLAYCOUNT,F*G rock.csv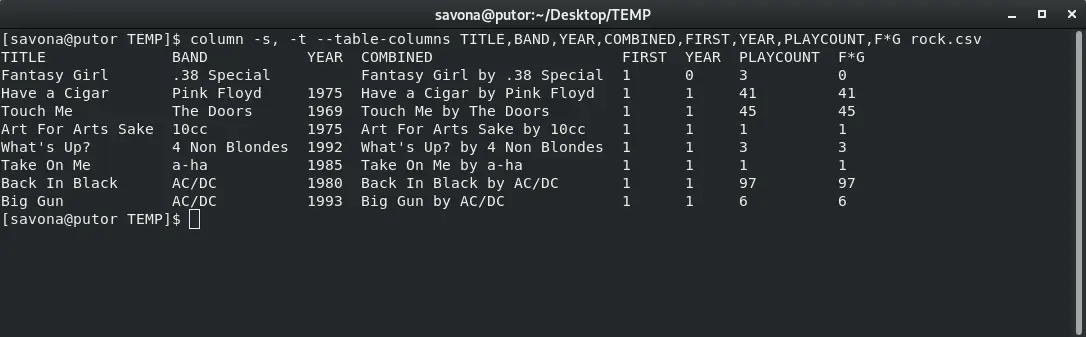
That is staring to look nice and clean.
Aligning Text in Columns
To further refine the output, we can align the text inside the columns to the right. Here we will use the –table-right ( -R ) option to align the last four columns to the right.
$ column -s, -t -N TITLE,BAND,YEAR,COMBINED,FIRST,YEARS,PLAYCOUNT,F*G -R FIRST,YEARS,PLAYCOUNT,F*G rock.csv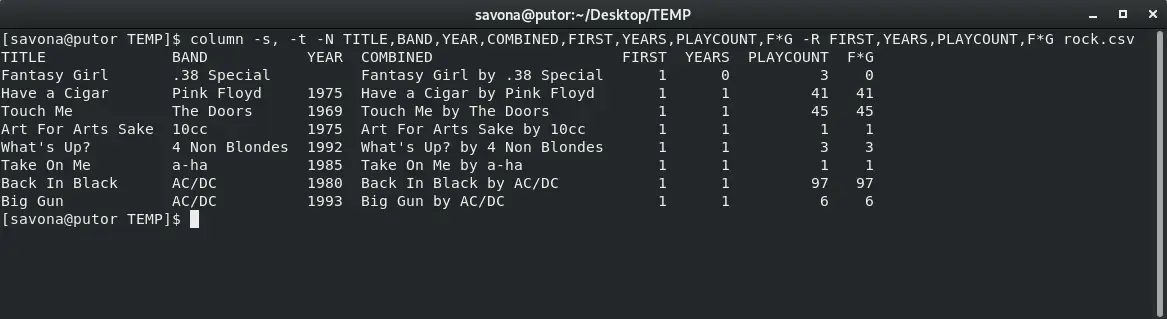
This aligned the numbers on the last four columns to the right making a clean look.
Hide Header Names
It is possible to hide the header names using the -d option. This allows you to use the header names for formatting (like aligning right) but not print the headers to standard output (STDOUT).
$ column -s, -t -d -N TITLE,BAND,YEAR,COMBINED,FIRST,YEARS,PLAYCOUNT,F*G -R FIRST,YEARS,PLAYCOUNT,F*G rock.csv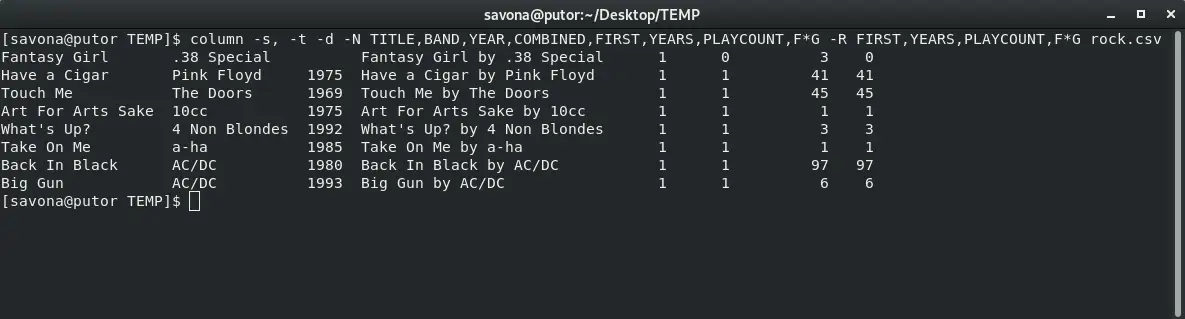
Truncate Long Strings
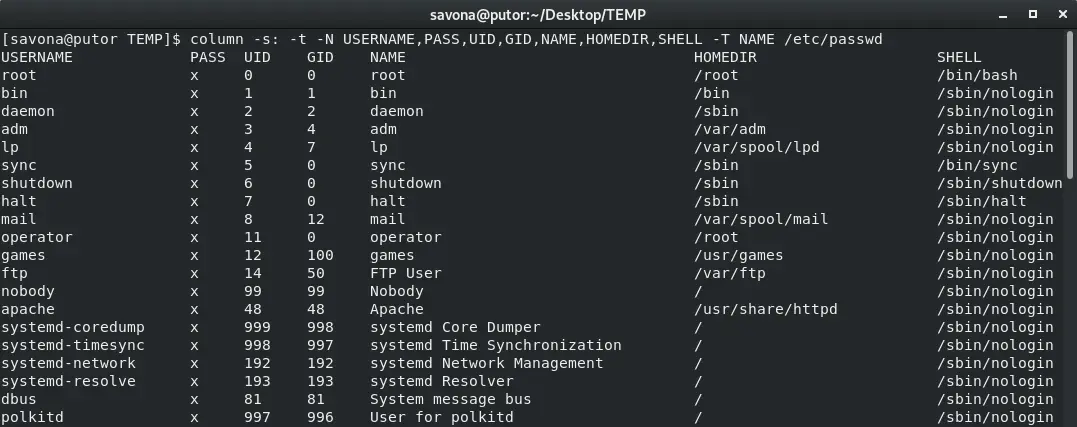
Using the –table-truncate ( -T ) option, you can specify the columns you will allow to be truncated. This helps when you have some columns that are unusually long, or a small terminal window. In this example we will print out the /etc/passwd file in columns. We are using a colon as our separator ( -s: ), defining that we want table output ( -t ), defining the column names ( -N ) and allowing the column NAME to be truncated ( -T ).
$ column -s: -t -n ROCK -N USERNAME,PASS,UID,GID,NAME,HOMEDIR,SHELL -T NAME /etc/passwd
Generating JSON Output with Column Command
You can easily print out a table in JSON format. Using JSON output requires the –table-columns ( -N ) option and column recommends having the –table-name ( -n ) set.
To output your table in JSON format, simply use the –json ( -J ) option.
$ column -s, -n Rock\ Playlist -J -t -d -N TITLE,BAND,YEAR,COMBINED,FIRST,YEARS,PLAYCOUNT,F*G rock.csv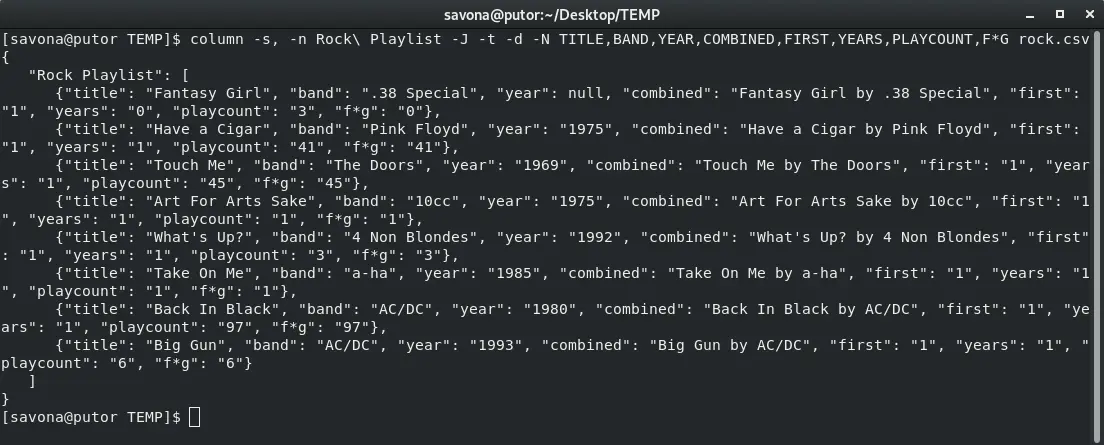
Conclusion
In my opinion the column command is a hidden gem. It may not be a widely used command, nor is it a command you will use every day. But, when the need arises, then it will be appreciated. Like my father always said “I would rather have it and not need it than need it and not have it”.
NOTE: I noticed Red Hat 7 and CentOS 7 ship with a stripped down version of the column command. There is no JSON output and other options are missing as well. I haven’t had time to fully investigate why. I will update this post when I find more information. This article was written on Fedora 29.
4.15.0-46-lowlatency #49-Ubuntu SMP PREEMPT Wed Feb 6 10:23:17 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
Ubuntu Studio
This has no JSON option either, which the JSON option really piqued my interest…..I’ll see what I find out about it too….
Great! Please come back and let us know what you find!
Thanks for calling attention to column. I may have been aware of it, but hadn’t used it, and may well have forgotten about it when I needed it. Less chance of that now. =:^)
On Gentoo (~amd64, ~arch compares to testing) here. Querying the package database says column is from util-linux, with v2.33.1 installed, and column /does/ have the JSON option. =:^)
Checking the util-linux NEWS and release-notes files I see in v2.30-ReleaseNotes:
column:
– add –json [Karel Zak]
So presumably distros missing column’s –json option are still running old util-linux versions from before the option was added in util-linux v2.30. That wouldn’t be surprising for enterprise distros where old and stale^H^Hble is a feature strongly preferred over whiz-bang new and potentially still buggy, particularly for older distro releases that are themselves a half-decade old or more.
Update: rpmfind.net lists only util-linux v2.23 for CentOS. Given that’s well before the v2.30 where –json was added, that indeed explains it for CentOS and RHEL, at least.
The column command lacks the one feature everyone wants – to be able to specify the number of columns.
I don’t want to have to specify column names to get a formatted table and I want to be able to say, “take this list of words and format them into a table with 16 columns”
e.g something like: column -t -cols 16 words.txt
is there a way to also keep the delimiter used in -s in the file … I use sed and would like to output a large file of sed commands used to modify data but use column to make the file easier to look at for errors … but I want to be able to keep the actual command as is just separated
eg: sed -i “s/Rock Band/Rock/g” file
sed -i “s/Rock Band /Rock/ /g”
I am not sure I know exactly what you are asking.
If you just want to see the file with spaces, you can use something like sed:
[savona@putor ~]$ sed -e ‘s#/#/ #g’ test
sed -i “s/ Rock Band/ Rock/ g” file
I am not sure why you would want to store the delimiter in a file, what is the advantage. I guess you can do some bash tricks like:
[savona@putor ~]$ cat delimiter
/
[savona@putor ~]$ column -s$(cat delimiter), -t test
sed -i “s Rock Band Rock g” file
In the above example I created a file called delimiter that had nothing but a forward slash in it. I think used shell replacement to place it in the command after the -s.
I hope this helps.
How about the –tree options of column?
The tree option isn’t used often. Do you think we should update the article to include it?
This was great.. I was excited to use it, than realized that RH7 doesn’t have half these options.. wondering why?